

DeepSeek-R1-Lite预览版的推出★,也标志着中国国产大模型在推理模型在实际应用中迈出了重要一步★★★。
DeepSeek(深度求索)是由幻方量化创始人梁文锋创立的AI初创公司,专注于开发通用人工智能(AGI)底层模型和技术★★。
例如★★★,DeepSeek V2模型的推理成本仅为每百万token 1块钱,远低于市场上的其他同类产品★★。这种架构创新不仅降低了显存占用,还减少了计算量,从而实现了成本的大幅下降★。
DeepSeek-R1-Lite模型的推出,标志着公司在推理模型领域的重要进展。
公司成立于2023年,源于梁文锋在量化投资领域的成功和对AI的热衷,幻方量化是国内量化私募领域的巨头之一★★,管理规模曾一度飙升至千亿,为DeepSeek提供了强大的资金和硬件支持★★★。
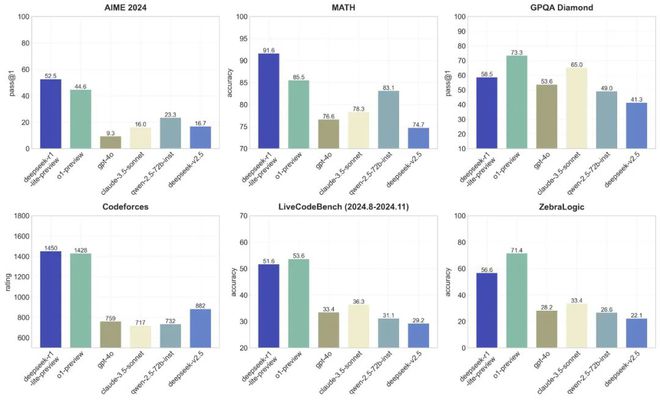
在具体的性能测试中★,DeepSeek-R1-Lite在美国数学竞赛(AMC)中难度最高的AIME赛事以及全球顶级编程竞赛Codeforces等评测中,均取得了优异的成绩,甚至超越了GPT-4o等知名模型★。
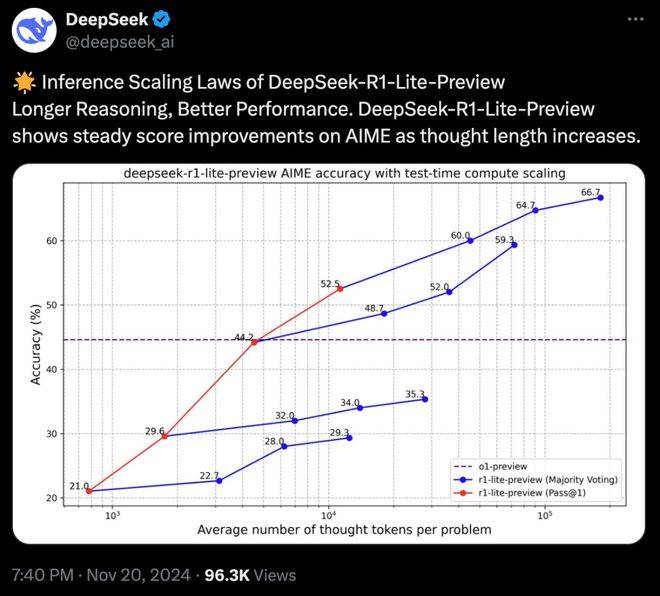
图★:DeepSeek-R1-Lite预览版的推理扩展法则★★,推理越深入,性能越好。
由此★★★,引发了中国大模型价格战,迫使包括字节、腾讯、百度、阿里等大厂纷纷降价。
DeepSeek的核心技术包括其创新的MLA(多头潜在注意力机制)架构和DeepSeekMoESparse结构。这些技术使得推理成本大幅降低。
不过★★,DeepSeek公司也透露,正式版的DeepSeek-R1模型将完全开源★★★,并公开技术报告以及部署API服务★★。
官方提供的数据显示,模型在数学竞赛上的得分与其所允许的思考长度紧密相关。
进一步验证了DeepSeek-R1-Lite在复杂逻辑推理任务上的强大实力。DeepSeek-R1-Lite的推理过程不仅长度可观,而且其包含的反思与验证环节也大大增强了其推理的准确性。
这一价格显著低于当前市场上的其他同类产品★★★,仅为GPT-4-Turbo价格的近百分之一★。
换句话说,给予模型更多的思考时间,其推理的准确率也会相应提升。尽管DeepSeek-R1-Lite已经展现出了强大的推理能力,但官方表示该模型目前仍处于迭代开发阶段。目前★,DeepSeek-R1-Lite仅支持在网页上使用,尚未开放API调用功能。
DeepSeek R1系列模型采用先进的强化学习技术进行训练★★,其推理过程深入细致★★★,并包含大量的反思与验证环节。
模型在思维链的长度上能够达到数万字的级别,并在数学★★、代码以及各类复杂逻辑推理任务上展现出卓越的性能★★★。





